
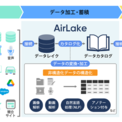
データサイエンスで企業と社会の課題を解決する株式会社DATAFLUCT(本社所在地:東京都渋谷区、代表取締役:久米村 隼人)は、社内に散在するデータや外部のオープンデータの集約のほか、非構造化データ[※1]の構造化などの前処理を簡単に実行しカタログ化するデータレイク/データウェアハウス『AirLake(エアーレイク)[※2]』の提供を12月中旬より開始します。
本サービスの利用を通じて、社内外の様々なデータを分析しやすい形に変換・加工し蓄積することで、良質なデータを基にした効果的なデータ活用を促進します。また、これまで組み合わせる機会のなかった非構造化データなどの多種多様なデータを掛け合わせられる環境を整え、新たなインサイトの理解や課題の解決につなげます。
※1 画像や動画、音声、文書など、そのままでは定型的に扱えないデータ。
※2 特許出願中。

- 「非構造化データ」に期待が集まるも、取り扱いの難易度は高い
データ活用の中でも現在とくに注目されているものが、画像や動画、音声、テキストなどの「非構造化データ」です。企業内のデータの約8割を占めているといわれている非構造化データは、新たな示唆の獲得や業務の新たな仕組みづくりの材料としての利用価値に期待が集まっています。
非構造化データはそのままの状態では活用できません。画像の場合、それが何を示しているかの情報を付与しなければならないほか、音声はテキスト化、Web上の文章はテキストからHTMLタグなどのノイズを除去するなど、対象データごとに適切な前処理を施さなければなりません。しかし、多種多様な前処理のノウハウをもつデータサイエンスに通ずる人材は限られる上に、外部に依頼する場合は大きなコストがかかることから、非構造化データを活用する難易度は高く、上手く活用できている企業は多くありません。

- Society5.0時代のデータ基盤を目指す『AirLake』
※3 画像や動画、音声、文書などの異なる様式のデータを統合的に処理すること。
※4 構造化・非構造化を問わずビッグデータをカタログ化し、ノーコード、エンドツーエンドで活用できる環境を提供する構想。詳細は、同日に発表したプレスリリース(https://datafluct.com/release/1718/)をご参照ください。
- 『AirLake』の特長
『AirLake』のデータ基盤テンプレートによって、データサイエンティストやエンジニアがいなくてもノーコードでアノテーション※5の実装が可能になり、非構造化データを構造化データへ簡単に変換・加工できます。本機能によってコストと工数を大幅に削減できるほか、これまでにないデータ同士の組み合わせから新たな洞察を得られる環境を整備できます。
<取扱い可能な主な非構造化データ[※6]>

※6 一部開発中。今後も順次ニーズに合わせた非構造化データに対応する予定です。現在の対応状況についてはお問い合わせください。
2.データの形式や社内外問わず、収集・管理が容易
様々なETLツールやVPN、APIといったコネクタを搭載し、社内・社外、構造化・非構造化を問わずどこからでも必要なデータを収集できます。また、収集したデータはカタログ化され、一元管理できます。堅牢なセキュリティにより、データごとに適切なアクセス権を付与することも可能です。
3.データ基盤の構築に必要な工数と費用を削減
PaaSとして提供するため、構築に伴う自社での設計や開発、テストの必要なしに迅速に導入いただけます。また、開発ベンダーによる大規模なインテグレーションも不要なため、初期コストと工数を従来よりも抑えられます。
4.当社の他サービスとシームレスな連携が可能
機械学習に必要な工程を一括で実行・管理・運用できるノーコードのエンドツーエンド機械学習プラットフォーム『DATAFLUCT cloud terminal.』やBIツールなど、当社の提供する各種分析系サービスとシームレスに連携できます。収集・加工・蓄積したデータを、最大限に活用できる環境をご用意します。なお、他社のデータサイエンスツール、AutoMLツール、BIツールにもご活用いただけます。
- 解決できる課題と期待できる効果
〔活用シーン1:文書検索の効率化〕
抱えている課題
社内で数多くの論文やドキュメントをpdf形式やword形式で保有しているが、一元管理できていない。論文・ドキュメントを探す際にファイル名で当たりをつけてからその中身までを確認しないと見つけられず、時間を要する。そのため、情報を探し出すには多くの関係者とコミュニケーションを交わさなければならないこともある。
活用法
『AirLake』に全ての論文とドキュメントファイルをインポート。情報探索型のテンプレートを利用し、自動的にファイルを分析してメタデータを付与し、活用できる形式に変換してから蓄積する。
効果
情報を探し出すやすくなり、業務効率が飛躍的に向上。他部門とのコミュニケーションも不要となり、全社的な作業工数の削減が実現。
データの種類
論文データ、ドキュメントデータ
〔活用シーン2:音声から感情を分析〕
抱えている課題
・営業の受注確率を向上させるために営業担当者の会話スキルを可視化し、適切なアドバイスを若手育成に活かしたい。
・ コールセンター業務で適切なクレーム対応ができず顧客満足度を下げてしまう課題を解決したい。
・ 蓄積した音声データの中から欲しいデータを検索する時間を短縮したい。
活用法
『AirLake』でテンプレートを利用して音声データを構造化し、可視化・検索できるようにする。また、機械学習により音声データの特徴を読み取ることで、話し手の感情を分析し活用する。
効果
個々の感覚や経験で取り組んでいた業務が客観的な数字として可視化できるようになり、適切なアドバイスや対応が可能になった。
データの種類
音声データ、動画データ
- 料金プラン
※ 上記の基本料金400,000円のほか、ストレージやトランザクション(それぞれ1TB以上から発生)の利用費、保守運用費、オプション利用費が追加されます。
■株式会社DATAFLUCTについて
2019年の設立以来「データを商いに」というビジョンのもと、活用されていないデータから新たなビジネスを創出し、企業と社会に価値を生み出しつづけるデータサイエンス・スタートアップスタジオです。衛星画像データから位置情報やPOSデータまで幅広い分析実績をもち、技術やデータにかかわらず業界をこえたアルゴリズム構築を得意としています。
食品流通から不動産分野まで多彩な自社サービスを開発する中で蓄積された知見を生かし、様々な企業のDX支援を行っています。またデータ活用によってSDGsに貢献することを目指し、ビジネスと社会貢献を両立させる新規事業開発にも積極的に取り組んでいます。2019年JAXAベンチャー※認定企業。
※宇宙航空研究開発機構(JAXA)の知的財産・業務での知見を利用して事業を行う、JAXA職員が出資・設立したベンチャー企業。
<企業概要>
本社所在地:東京都渋谷区道玄坂一丁目19番9号 第一暁ビル6階
代表者:代表取締役 久米村 隼人
設立:2019年1月29日
電話番号:03-6822-5590(代表)
資本金:4億4,712万円(資本金準備金含む)
事業内容 :マルチモーダルデータ活用サービス(AI/機械学習/ビッグデータ解析)の提供、企業のDX支援
WEBサイト:https://datafluct.com/
Twitter: https://twitter.com/datafluct
Facebook: https://www.facebook.com/datafluct/
note: https://note.datafluct.jp/
<本件に関するお問い合わせ>
株式会社DATAFLUCT
Tel:03-6822-5590
Mail:info@datafluct.com
配信元企業:株式会社DATAFLUCT

コメント