
SyntheticGestalt(東京都新宿区、代表 島田幸輝。以下「当社」)は、2024年3月22日(金)16時に当社の研究開発の成果である、低分子に特化した大規模事前学習モデルについて発表予定ですので、お知らせいたします。発表はNVIDIA主催のAI 時代を牽引する技術カンファレンス、「GTC」にて、オンラインで行われます。
タイトル:10億化合物を学習させた大規模事前学習モデルによる次世代AI創薬
/ One billion compounds to empower next-gen AI drug discovery: a case study in the use of large-scale pre-training [SE62873]

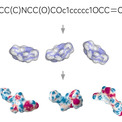
大規模事前学習モデルの特徴である、化合物表現のイメージ図
本発表は、「学習したデータから離れたデータに対してはAIがうまく予測できない」という、AI創薬最大の課題について、10億件という大規模な学習データを用いることで大幅な精度の向上を達成し、一つの解決策を提案するものです。分子に特化した大規模事前学習モデルは他社でも開発されておりますが、学習データ量、学習に利用している化合物の特徴量の複雑さ、いずれにおいても世界最大のモデルになります。
弊社リサーチエンジニアのSouradip Mookerjee博士がプレゼンターを務め、学習データから大きく離れたデータに対して当社の大規模事前学習モデルを利用した予測を行い、実際に実験で計測した数値(初期毒性や薬物動態パラメータ)に対する予測精度から、有用性を示します。
また、この予測精度の大幅向上に貢献した大規模事前学習モデルは、他の様々な分子探索プロジェクトに活用することができ、より高精度なモデルを簡単に開発できる旨もご紹介します。
視聴方法
NVIDIA GTC Day: https://www.nvidia.com/gtc/
に登録の上、下記レクチャーの視聴登録をしていただければ、3月22日16:00~16:25にてご視聴いただけます。
配信元企業:SyntheticGestalt株式会社

コメント