
【研究の要旨とポイント】
-
全結合型イジング半導体システムの大規模化実現に向けて、複数のLSIチップを用いたスケーラブル化技術の実機検証に成功し、大容量化にめどをつけました。
-
22nm CMOS演算LSIチップ36個+制御FPGA1個を用いて、4096スピン搭載のスケーラブル全結合型イジングプロセッシングシステムを実現しました。
-
PCでの全結合イジングシステムを模したアニーリングエミュレーションと比較して、2,306 倍、コア部同士(CPUと演算チップ)での比較では2,186 倍の電力性能比を達成しました。
-
本技術は2030年までに2M個のスピン実現を目指しており、それが可能になれば、2050年ごろの量子コンピュータと同等の計算能力を、空調・大型施設が不要かつ、現状の半導体プロセスで実現できると期待されます。
【研究の概要】
東京理科大学工学部電気工学科の河原尊之教授の研究グループは、複数の22nm相補型金属酸化膜半導体(CMOS)チップで構成されたスケーラブルな全結合半導体イジングプロセッシングシステムを開発しました。PCでの全結合イジングシステムを模したアニーリングエミュレーションと比較して、2,306倍、コア部同士(CPUと演算チップ)での比較は2,186倍の電力性能比を達成しました。更に開発したシステムはスピンスレッドを用いた8並列の解探索を実現しており、高精度な探索が可能となります。
集積回路(LSI)で実現するイジングマシンは、量子コンピュータの開発に触発されて研究が進んでいる量子Inspired技術の一つです。従来のコンピュータよりも組み合わせ最適化問題を高速に解くことができるのが大きな特徴です。
全結合型イジングLSIは、汎用性は高いものの、全結合なので、1チップ搭載そのもの、および複数個のチップに分けることが困難と考えられてきました。そうした状況の中、河原教授らは2020年、独自の処理アーキテクチャにより、1チップでの全結合型LSIを28nmCMOS技術にて実現しました(※1)。そしてアニーリング方式を用いた一つの全結合システムとして作動する大規模イジングLSIシステムを構成するために、2022年、並列動作させた複数のチップを用いて大規模化を図るスケーラブルな全結合型方式を考案し、FPGAを用いて384スピンの全結合アニーリング処理イジングシステムボードを作成しました(※2)。
※1 「世界で初めての全結合型半導体アニーリング方式人工知能チップを開発 ~512スピン実装により22都市巡回セールスマン問題求解を瞬時に(ノイマン型高性能CPUではおよそ1200年が必要)~」
https://www.tus.ac.jp/today/archive/20200122003_1.html
※2 「量子Inspired技術の新展開:スケーラブルな全結合型イジング半導体システム ~組み合わせ最適化問題求解を低消費電力かつ高速に行う技術の基礎検証に成功~」
https://www.tus.ac.jp/today/archive/20220928_5268.html
今回、22nm CMOS技術で作成した演算LSIチップ36個と制御用のFPGA1個を用いて、4,096スピンを持つスケーラブル全結合型イジングプロセッサを実現しました(図1)。独自技術を用いて従来方式より必要チップ数を約半減しつつ、スピンスレッドを用いた8並列の解探索により、組み合わせ最適化問題の高速かつ高精度な求解を可能にしました。
例題として、4,096頂点の頂点被覆問題(組み合わせ最適化問題の代表的な問題の一つ、*1)を開発した実機で解いたところ、3.6GHz動作のCPUを持つPCで全結合イジングシステムを模したアニーリングエミュレーションよりも、2,300倍以上エネルギー効率が高い性能となりました。
本研究成果は、2024年1月30日に国際学術誌「IEEE ACCESS」にオンライン掲載されました。
※PR TIMESのシステムでは上付き・下付き文字を使用できないため、正式な表記と異なる場合がございますのでご留意ください。正式な表記は、東京理科大学WEBページ(https://www.tus.ac.jp/today/archive/20240321_9493.html)をご参照ください。

図1. 本研究で開発した22nm CMOS全結合型イジングLSIチップ(a)と、それらを結合した4,096スピンスケーラブル全結合型イジングLSIシステム(b)。
本研究グループは、クラウドを含めた空調・大規模施設が不要で、エッジでの高速な情報処理を実現することを目標としています。今後、本技術を順調に発展させることができれば、2030年には、2050年頃に量子コンピュータが到達すると予想されている性能と同等の性能を達成できると期待されます。具体的には、本技術は2030年までに2M個スピンを実現することを目標としています。
本研究室では、本技術を利用した新たなデジタル産業の創出を目指しています。本研究の社会実装に向け、本研究室との連携に興味をお持ちの企業の方は、ぜひご連絡ください。
【研究の背景】
全結合型イジングプロセッサでは、組み合わせ最適化問題の複数の解の候補についてイジングモデルを用いて、複数個のスピンのデータと、スピン同士を結合させる強さを格納した回路(結合セル)のデータを使った個々のスピン間の関係で表現します。これらのデータを用いて、積和演算(乗算の結果を順次加算する演算)を行い、この結果を用いて、アニーリング方式でイジングモデルでの系全体のエネルギーが最低となる状態を求めます。このエネルギーが最低となる状態が、組み合わせ最適化問題の解を示します。
具体的には、イジングモデルでの系全体のエネルギーはE=-Σ_(i,j) J_i,j σ_i σ_j -Σ_i h_i σ_iと表すことができます(σはスピン、Jはスピン間相互作用、hは外部磁場)。ですので、このEが小さくなるようにσ_iとσ_jを更新するのが、イジングモデルを用いた解の求め方です。しかし全結合型では全てのi,jで積和をとるため、従来の方法では配線が非常に複雑となっていました。
河原教授らが2020年に発表した方法では、ΔE_i=Σ_j J_i,j σ_j+ h_iの値を用いてσ_iを更新する方式を採用することで、複数のチップでも∆E_iのみのやりとりで演算が可能になりました。これにより、全結合のまま複数チップへの拡張が容易となり、2020年、28nm CMOS技術にて1チップでの全結合型LSIを実現しました(※1、図2a)。そして2021年には、FPGAを用いたスケーラブル384スピン全結合システムFPGA検証ボードを国際展示会CEATEC 2021 ONLINEで公開し、2022年、同手法を論文として発表しました(※2)。
今回、22nmCMOS技術で作成した複数のLSIチップを用いて、全結合型イジング半導体システムのスケーラブル化技術の実機検証を行いました。

図2. これまでに本研究グループが開発した全結合型イジング半導体システム。
【研究結果の詳細】
今回、22nm CMOS技術で作成した演算LSIチップ36個と制御用のFPGA1個を用いて、4,096スピンを持つスケーラブル全結合型イジングプロセッサを実現しました(図1)。このシステムでは、従来方式よりも必要チップ数を約半減できる相互作用半減実装方式を考案しました。また、スピンスレッド(あたかも複数回の動作を一度に行うことができる)を8個搭載しているため、1回のデータの出し入れで8回分の計算が1度にできます。なお、相互作用半減実装方式およびスピンスレッドは、いずれも本学の独自技術です。
このシステムは10Mhzで動作し、ボード全体の電力は2.9Wでした。このうち、22nmCMOS演算LSIチップ36個の電力は1.3Wでした。
例題として、4096頂点の頂点被覆問題を開発した実機で解いたところ、3.6GHz動作のCPUを持つPCで全結合イジングシステムを模したアニーリングエミュレーションよりも、2,306倍もエネルギー効率が高い性能となりました(図3)。コア部同士(CPUと演算チップ)での比較は2,186倍の電力性能比を達成しました。また、本システムはスピンスレッドを用いた8並列ですので、高精度な探索が可能となります。

図3. 4096頂点の頂点被覆問題の求解結果の比較。
【今後の展望】
量子コンピュータは社会変革を起こす技術として研究開発が盛んに進められており、20年から30年後の商業実用化が見込まれています。量子コンピュータの活用により、組み合わせ最適化問題の解を高速に得ることができるようになると期待されています。
組み合わせ最適化問題は、膨大な選択肢の中から最適な解を導き出す問題のことを指します。創薬・新素材開発、物流・送電経路探索、倉庫・施設管理最適化、人員・生産計画、多地点無線通信路探索、金融ポートフォリオ、マーケティングなど、幅広い分野で直面する課題は、組み合わせ最適化問題として定式化することができます。そのため、組み合わせ最適化問題を解くことができる量子コンピュータへのニーズは今後ますます拡大すると期待されています。
一方で、量子コンピュータの稼働には極低温を維持する必要があり、膨大なエネルギーを消費します。そのため、組み合わせ最適化問題求解においては、空調や大型設備が不要なアプローチも重要となります。
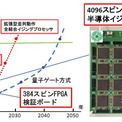
量子コンピュータよりもはるかに省エネルギーで稼働する全結合型イジング半導体モデルは、組み合わせ最適化問題求解に向けた有望な技術として期待されています。今後、本技術を順調に発展させることができれば、2030年には、2050年頃に量子コンピュータが到達すると予想されている性能と同等の性能を達成できると期待されます(図4)。具体的には、2030年には2M個スピンを実現することを目標としています。

図4. 本技術の今後の展望。
本研究室では、本技術の早期の社会実装および本技術を利用した新たなデジタル産業の創出に取り組んでいく予定です。本研究室との連携に興味をお持ちの企業の方は、ぜひご連絡ください。
※本研究は、日本学術振興会科学研究費補助金(22H01559)、東京理科大学起業助成金(PoC支援助成金)、東京都の「大学発スタートアップ創出支援事業」の助成を受けて実施したものです。
【用語】
*1 頂点被覆問題
グラフ理論における古典的な組み合わせ最適化問題。複数の頂点とそれを結ぶ辺があったとき、全ての辺において、少なくともその始点または終点のいずれかが、クラス分けした頂点群のうちの一方のクラスに属する少なくとも一つの頂点と接するもので、そのクラスを最小にする問題。

【論文情報】
雑誌名:IEEE ACCESS
論文タイトル:Scalable Fully-Coupled Annealing Processing System Implementing 4096 Spins Using 22nm CMOS LSI
著者:Taichi Megumi, Akari Endo, and Takayuki Kawahara
DOI:10.1109/ACCESS.2024.3360034
URL:https://doi.org/10.1109/ACCESS.2024.3360034
※本論文はオープンアクセスです。どなたでもダウンロードできます。
【発表者】
惠 太一 東京理科大学大学院工学研究科電気工学専攻 修士課程2年 <筆頭著者>
遠藤 あかり 東京理科大学大学院工学研究科電気工学専攻 修士課程2年
河原 尊之 東京理科大学工学部電気工学科 教授 <責任著者>
【関連国際学会】
学会名:IEEE 22nd World Symposium on Applied Machine Intelligence and Informatics (SAMI 2024) (「IEEE 第22回応用機械知能と情報学に関する世界シンポジウム」)
論文タイトル:Fabrication and Evaluation of a 22nm 512 Spin Fully Coupled Annealing Processor for a 4k Spin Scalable Fully Coupled Annealing Processing System
著者:Akari Endo, Taichi Megumi, and Takayuki Kawahara
発表日:2024年1月25日(木)
DOI:10.1109/SAMI60510.2024.10432908
URL:https://doi.org/10.1109/SAMI60510.2024.10432908
【発表者】
遠藤 あかり 東京理科大学大学院工学研究科電気工学専攻 修士課程2年 <筆頭著者>
惠 太一 東京理科大学大学院工学研究科電気工学専攻 修士課程2年
河原 尊之 東京理科大学工学部電気工学科 教授 <責任著者>
【動画】
本研究成果をまとめた動画(英語版)も公開しておりますので併せてご参照ください。
・動画タイトル:A Scalable Annealing Processor for Enhanced Problem Solving
・東京理科大学YouTube:https://youtu.be/9BYgJRXxd0E
(※日本語字幕版を近日公開予定)
配信元企業:学校法人東京理科大学

コメント